
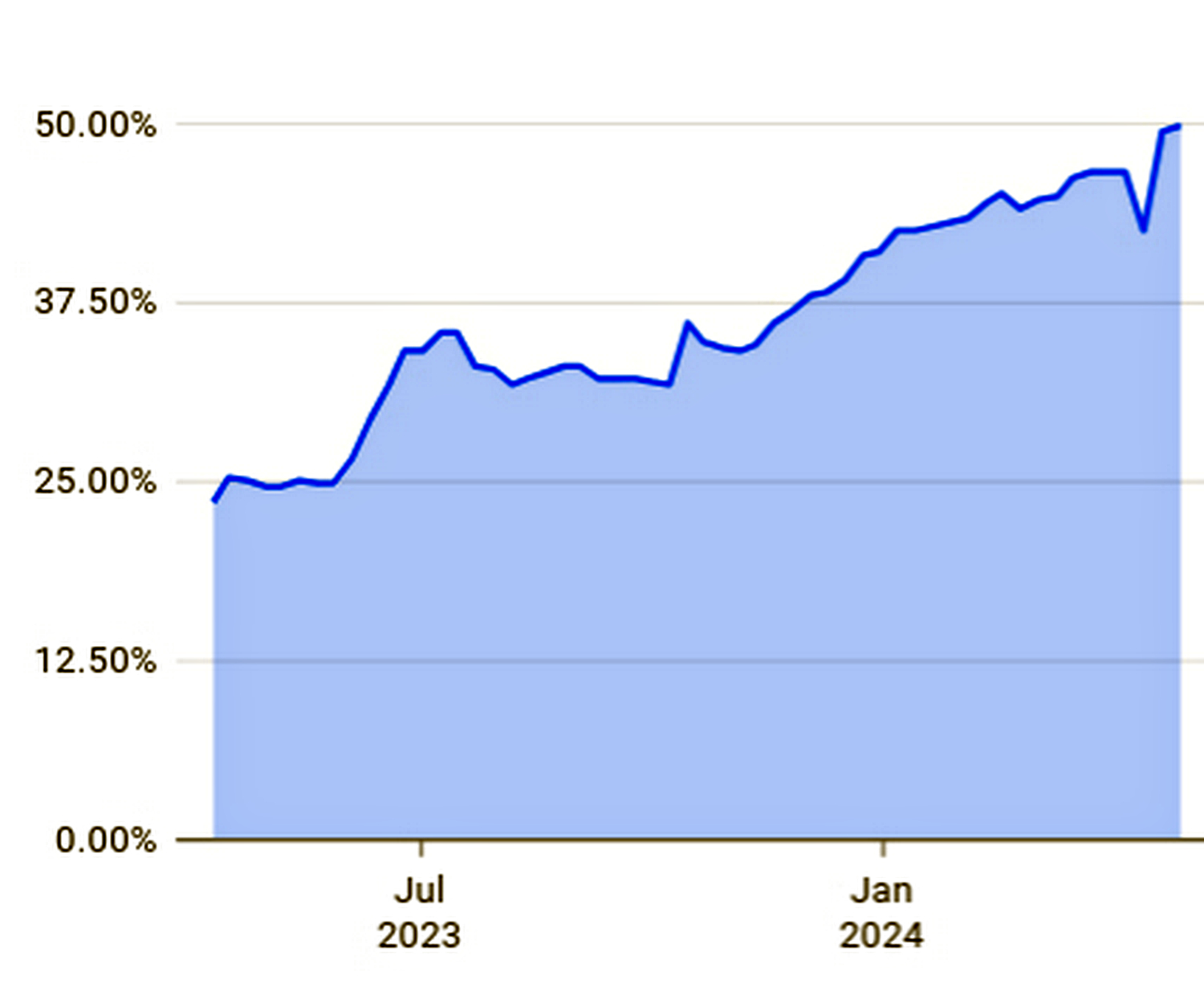
Як інформує «Kreschatic» з посиланням на статистику, оприлюднену на сторінці Google, ШІ-моделі дедалі частіше використовуються для написання програмного коду компанії.
Згідно з даними Google, наразі розробники приймають близько 37 відсотків пропозицій ШІ, і ці підказки лежать в основі приблизно 50 відсотків коду, який створюється всередині компанії. ШІ також бере участь у 8 відсотків виправлень у процесі перегляду/рецензування та адаптує 2 відсотки повторно використовуваного коду. Хоча всі пропозиції ШІ все ще вимагають перевірки фахівцями, вони допомагають значно знизити рутинне навантаження і дають можливість зосередитися на архітектурі та проєктуванні рішень.
Розробники дедалі частіше взаємодіють із моделлю за допомогою звичайної мови — ШІ інтерпретує команди та пише код на їхній основі, але ключовим елементом у цій процедурі є якість даних.
Зокрема, в Google, для навчання моделей Gemini використовується власний датасет DIDACT, що включає логи збірок, виправлень і код-аналізування, накопичені за роки. При цьому в корпорації наголошують на важливості інтеграції ШІ в комфортний робочий процес: без продуманого інтерфейсу навіть найбільш просунута модель може виявитися малоефективною.
Раніше ми писали про те, чи дійсно штучний інтелект підвищує продуктивність.